Vector and Scalar Projections
CS-466/566: Math for AI
Module 02: Computational Linear Algebra-1
2026-03-23
Motivation: Why Geometry Matters in ML
Data lives in vector spaces. Learning depends on distance, similarity, and direction.
Geometry explains:
- Clustering
- Cosine similarity
- PCA / projections
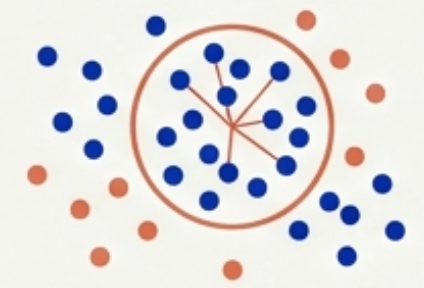
Geometry gives meaning to the data.
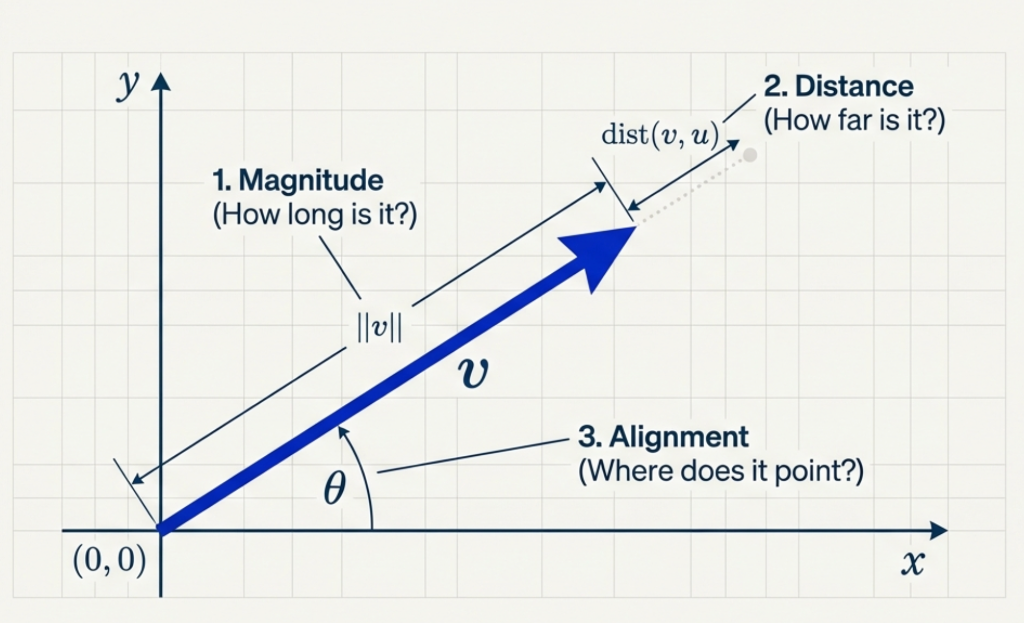
Vectors as Geometry
- A vector is an arrow from the origin
- Geometry asks:
- How long is it?
- How far apart are two vectors?
- How aligned are they?
These questions lead to norms and inner products.
Norms: Measuring Size
A norm is a function that takes a vector and returns a non-negative number: \(V \to [0,\infty)\)
\[\|x\| \]


Triangle inequality
Common Norms in \(\mathbb{R}^n\)
Euclidean (\(\ell_2\)) – Most common in ML 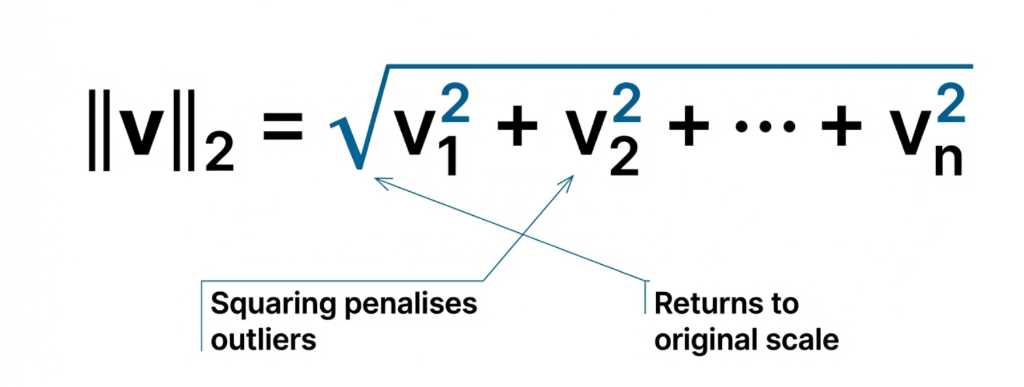
Manhattan (\(\ell_1\)) – Used in regularization 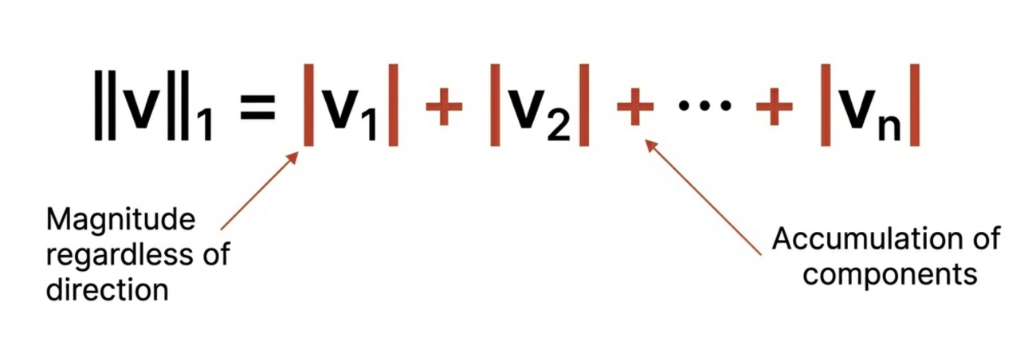
Supremum (\(\ell_\infty\)) – Largest component 

L1 vs L2 distance comparison
Visualizing the Unit Ball
Visualising the ‘Unit Ball’ (points where distance is 1) for different norms.
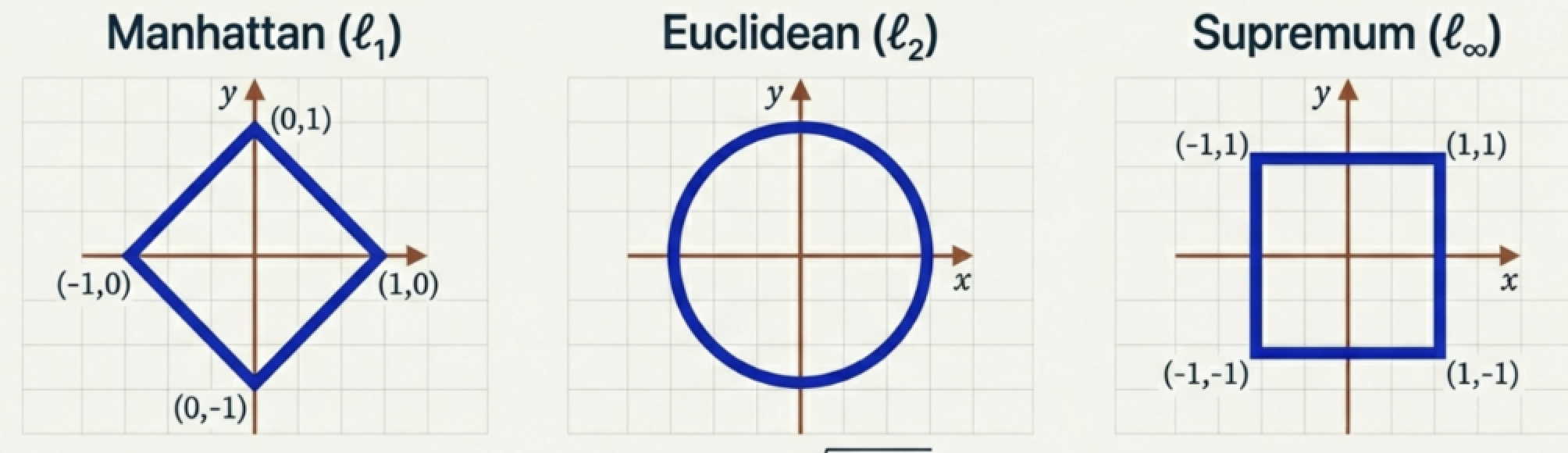
- Manhattan (\(\ell_1\)): Diamond shape
- Euclidean (\(\ell_2\)): Circle (familiar distance)
- Supremum (\(\ell_\infty\)): Square
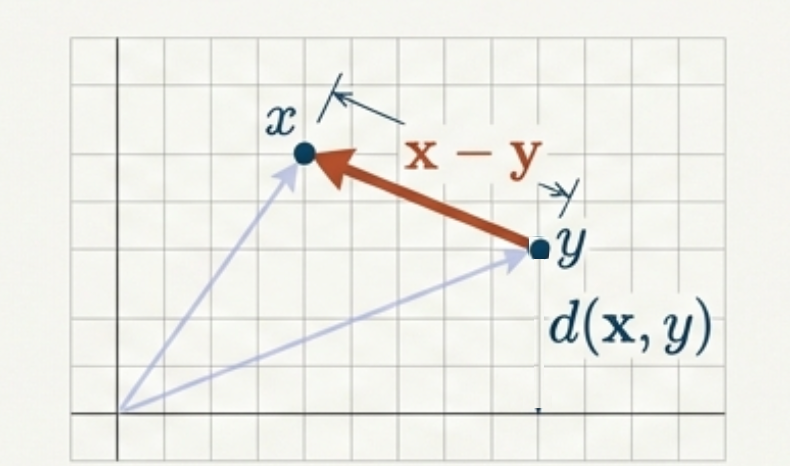
Distance from Norms
Given a norm, define distance:
\[d(x,y) = \|x - y\|\]
Properties:
- Nonnegative
- Symmetric
- Triangle inequality:
\(d(x,z) \leq d(x,y) + d(y,z)\)
Distance = length of displacement
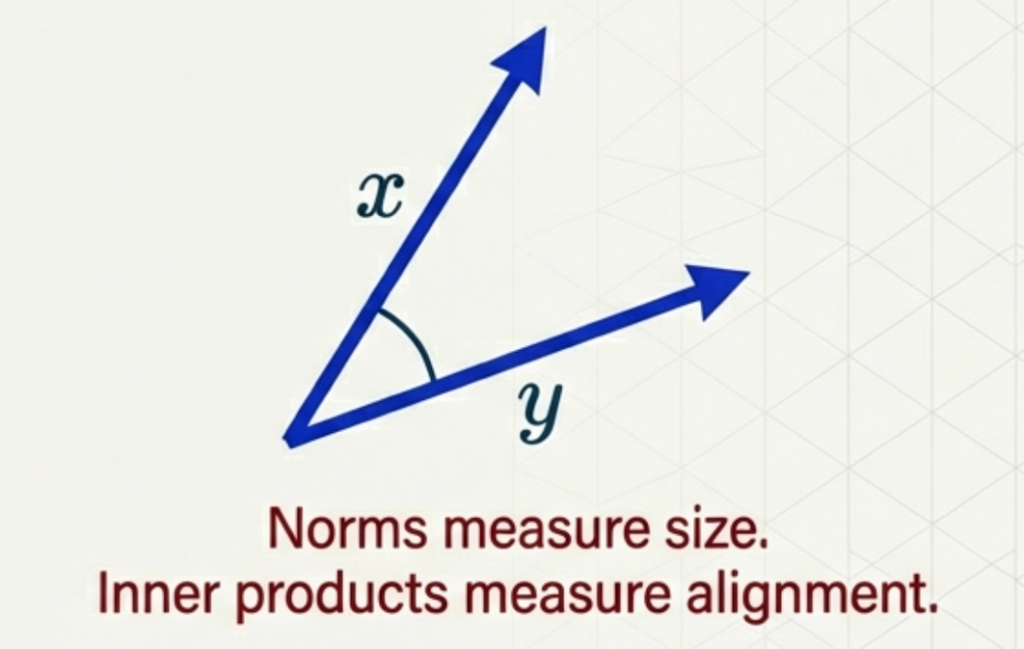
Inner Products: Measuring Similarity
An inner product is a function \(\langle \cdot, \cdot \rangle : V \times V \to \mathbb{R}\) satisfying:
Definition properties:
Linearity
e.g., \(\langle \alpha x , y \rangle = \alpha\langle x,y \rangle = \langle x,\alpha y \rangle\)Symmetry
e.g., \(\langle x,y \rangle = \langle y,x \rangle\)Positive Definiteness
e.g., \(\langle x,x \rangle \ge 0\) ; \(\langle x,x \rangle = 0 \iff x = 0\)
The Standard Dot Product:
\[\langle x, y \rangle = \sum_i x_i y_i = \|x\|\|y\|\cos(\theta)\]
Inner product between vector and itself is the norm squared!
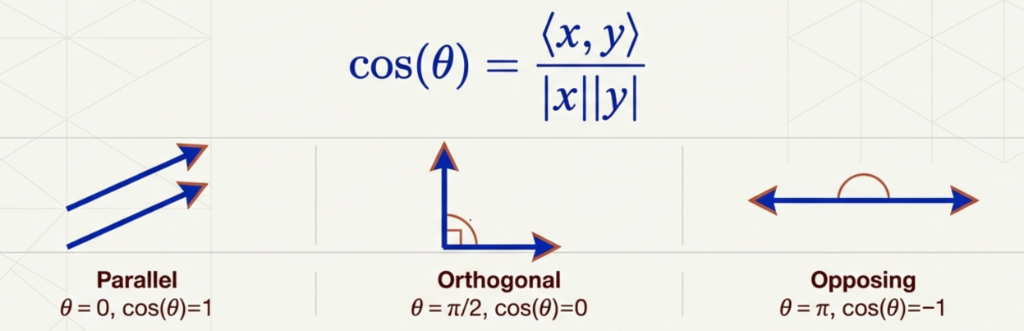
Angles and Similarity
Defined via:
\[\cos(\theta) = \frac{\langle x,y \rangle}{\|x\|\,\|y\|}\]
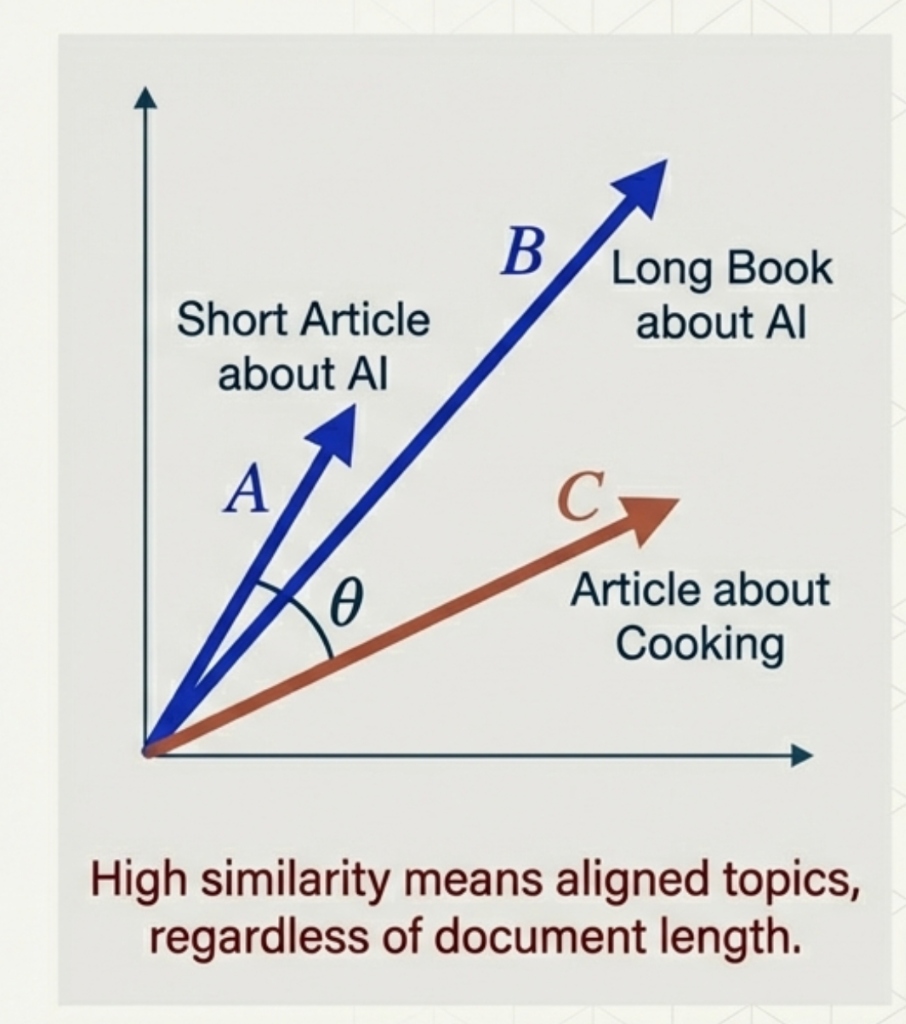
Cosine Similarity
In high-dimensional spaces (like text analysis), we often care about direction, not magnitude.
\[\text{Cosine Similarity} = \frac{\langle x, y \rangle}{\|x\| \|y\|}\]
Orthogonality
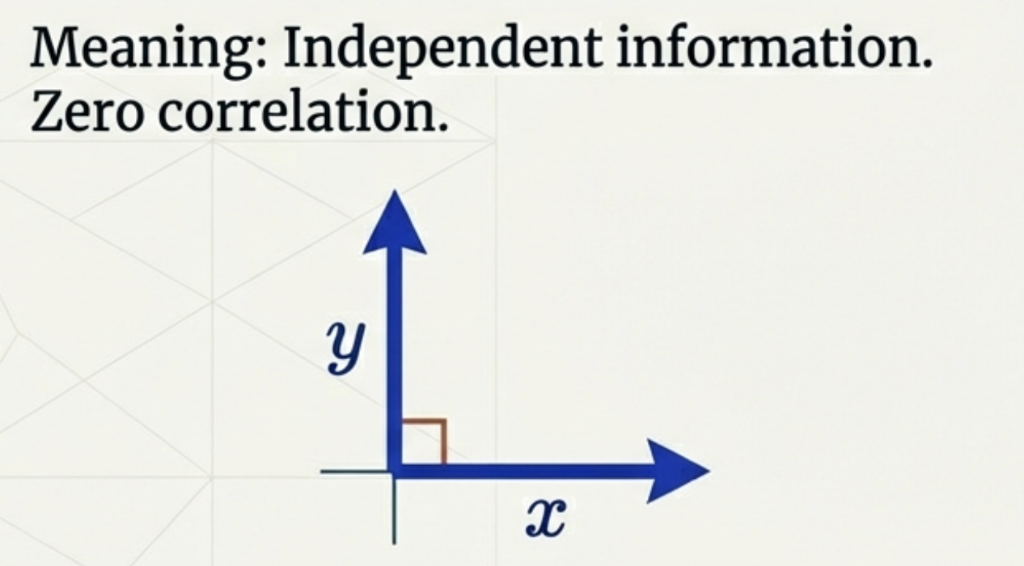
Two vectors are orthogonal if:
\[\langle x,y \rangle = 0\]
Interpretation:
- No shared information
- Independent directions
- Perpendicular in geometric space
Orthonormal Bases
A basis \(\{v_i\}\) is orthonormal if every vector has unit length and all are mutually orthogonal.
Conditions:
- \(\|v_i\| = 1\)
- \(\langle v_i, v_j \rangle = 0\) for \(i \neq j\)
Why use orthonormal bases?
- Coordinates are easy: Direct projection (\(x_i = \langle x, v_i \rangle\))
- Norms are simple: Pythagorean theorem holds (\(\|x\|^2 = \sum x_i^2\))
- Computations decouple: Each dimension is independent

Standard orthonormal basis in \(\mathbb{R}^3\)
Exercise: Orthonormal Basis
Is the set \(S\) an orthonormal basis for \(\mathbb{R}^2\)?
\(S = \left\{ \begin{bmatrix} \frac{1}{\sqrt{2}} \\ \frac{1}{\sqrt{2}} \end{bmatrix}, \begin{bmatrix} \frac{1}{\sqrt{2}} \\ -\frac{1}{\sqrt{2}} \end{bmatrix} \right\}\)
Check Conditions:
- Unit Length? Yes.
\((\frac{1}{\sqrt{2}})^2 + (\frac{1}{\sqrt{2}})^2 = \frac{1}{2} + \frac{1}{2} = 1\)
- Orthogonal? Yes.
\(\frac{1}{\sqrt{2}}(\frac{1}{\sqrt{2}}) + \frac{1}{\sqrt{2}}(-\frac{1}{\sqrt{2}}) = \frac{1}{2} - \frac{1}{2} = 0\)
Conclusion: Yes, it is an orthonormal basis!
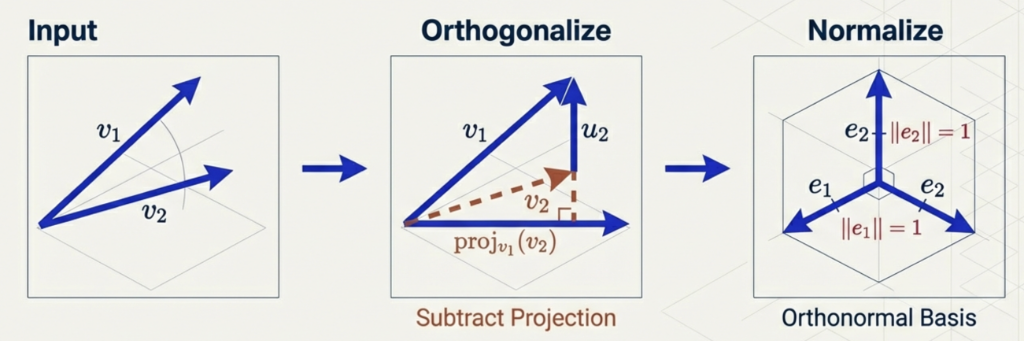
Gram–Schmidt Orthogonalization
Goal:
Convert any linearly independent set into an orthonormal basis
Algorithm:
- Start with basis
- Orthogonalize
- Normalize
Thank You!


